Scraped data
Legally radioactive
Consent cannot be retrofitted. Bot-blocking and copyright litigation closed this path, and every model trained on scraped video carries the liability forward with it.
 Diffraction
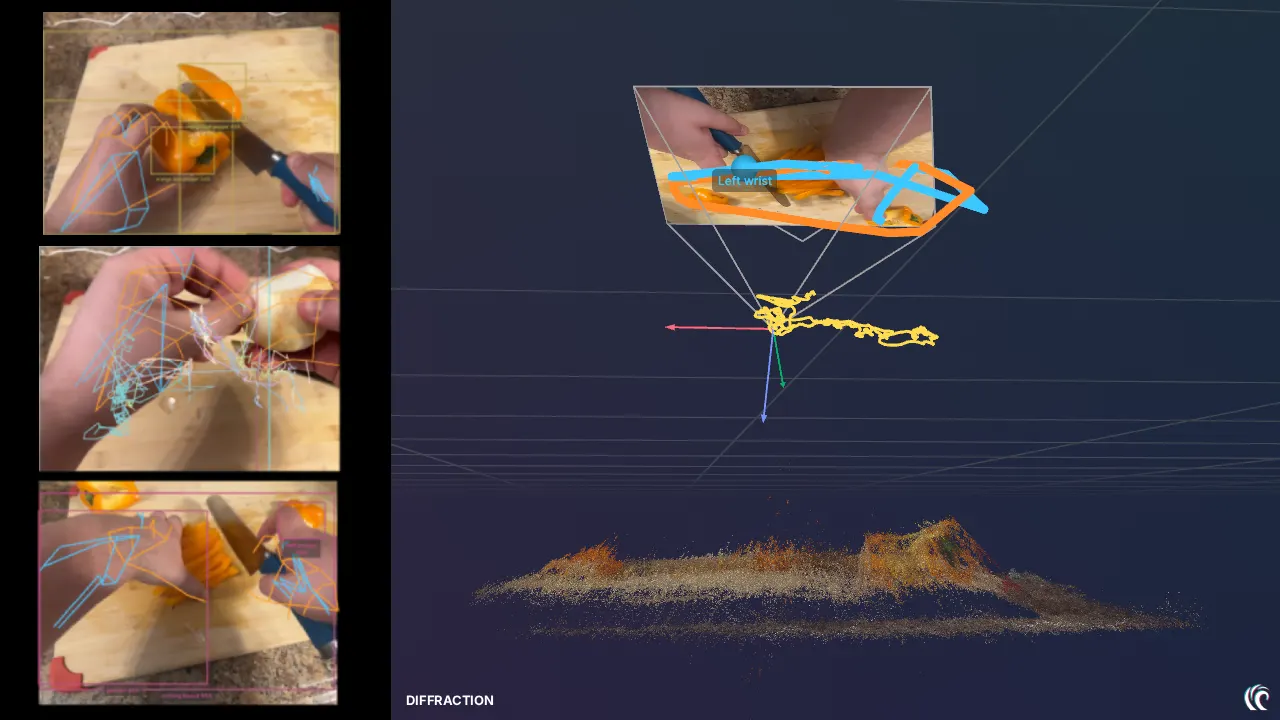
Diffraction Almost all training video is footage that happened to exist. The POD is the opposite: a calibrated capture instrument where trained, fairly-paid operators perform real tasks under synchronized egocentric and exocentric rigs. Every camera is measured. Every hand is tracked. Every consent is signed. Physical AI gets built on that difference.
The AI industry needs millions of hours of real-world human video, and the honest version of the sourcing story is uncomfortable:
Consent cannot be retrofitted. Bot-blocking and copyright litigation closed this path, and every model trained on scraped video carries the liability forward with it.
Renderers still fail at contact, friction, and deformation — exactly the events a manipulation policy has to learn. Synthetic data is a supplement, not a source.
An uncalibrated camera produces pixels, not measurements. Annotation after the fact is estimation — you cannot recover signal that was never captured.
One-off collection produces beautiful demos that can't scale, can't be reproduced, and can't be audited. A dataset you can't re-run is a dataset you can't trust.
A purpose-built capture studio with controlled lighting and a measured geometry. Because the environment is fixed and calibrated, every hour captured inside it has properties in-the-wild footage structurally cannot have.
Egocentric (head-mounted) and exocentric (room-mounted) rigs record the same act on a shared clock. Cross-view correspondence is a property of the capture — not a guess made later.
Known camera intrinsics and extrinsics make reconstruction metric: positions in meters, camera trajectories you can measure against, depth that is real rather than inferred.
Same room, same lighting, same rig. Tasks can be re-run, datasets re-validated, and any error traced back to a specific session — the same standard a lab applies to its own experiments.
Trained, fairly-paid local performers execute structured task protocols — cooking, cleaning, manipulation, navigation — consistently enough to be a controlled variable, not a source of noise.
Consent and licensing are captured at the door, cryptographically signed, and travel with every asset derived from the session. Revocation propagates — even to datasets already delivered.
Both frames below are unretouched pipeline output from real capture sessions — the same artifacts a buyer receives.

Raw video in. The untouched original is preserved; a clean, standardized working copy moves down the line.
Speech, captions, hand & body pose, depth, camera trajectory, object detection, 3D scene reconstruction — extracted automatically, 60+ metadata fields per segment.
A cryptographically signed certificate: who consented, under what license, when — plus a tamper-proof fingerprint of the footage itself.
Every dataset is scored against the buyer's spec before it ships. Misses are flagged by us — not discovered by you.
WebDataset for frontier labs. RLDS — the standard robot-training format — for robotics labs.
The industry films first and labels later. We instrument the room so pose, depth, and trajectory are measured properties of the session. Post-hoc annotation estimates; an instrument records.
Research proved the paired ego/exo format is what embodied AI needs — then licensed it for academia only. We manufacture it as a commercial product, with the legal chain to sell it.
A performer can withdraw, and the withdrawal reaches datasets we've already delivered. It costs us margin. We do it anyway, because provenance you can't revoke is provenance you can't trust.
A 4-hour session becomes a certified, annotated dataset in 10–15 minutes. Those numbers are pipeline telemetry, not a sales projection.
Robotics and frontier AI teams from pre-seed to Series B use our datasets. Every asset ships with provable consent, licensing, and provenance — built for an era of AI copyright litigation and EU AI Act transparency. And if found footage is genuinely good enough for your problem, we'll tell you that too.